
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Linux세팅
- ThreadGroup()
- isinterrupted()
- 상관서브쿼리
- 상관 서브 쿼리
- ID중복
- 리눅스세팅
- char[] String 형변환
- StringReader
- MemoryStream
- first-of-child
- 동기화
- 스레드그룸
- StringWriter
- 메모리스트림
- 표현 언어
- 아이디중복
- include 지시자
- sleep()메소드
- include지시자
- String char[] 형변환
- interrupted()
- interrupt()
- first-child
- Linux셋팅
- InputDialog
- ObjectInputStream
- 리눅스셋팅
- Daemon()
- include액션태그
- Today
- Total
다연이네
[days06] SQL function 이어서 본문
1. emp 테이블에서 평균급여(pay) 보다 사원급여가 같거나 크면 good ,작은면 poor 출력
( 조건 : 평균급여와 사원급여의 차액도 출력 )
with temp as( --밑에서 'pay'를 쓸 수 있게 with절로 한다
select ename,sal+nvl(comm,0) pay
,(select trunc(avg(sal+nvl(comm,0))) 평균급여 from emp) avg_pay
from emp
)
select temp.* --그냥 별사탕 주면 오류고 temp.*하면 갠춘
--,sign(pay-avg_pay)
,to_char(pay - avg_pay,'S9999') "평균과 차액" --s의 의미 : 양수는+ 음수는- 기호 붙히겠다
,case
when (pay-avg_pay)>=0 then 'good'
when(pay-avg_pay)<0 then 'poor'
end "평가"
,decode(sign(pay - avg_pay), -1, 'poor', 'good') "디코드"
from temp;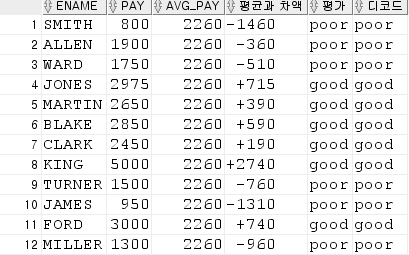
2. emp 에서 decode(), case 사용해서 10번 5%,20번 20%, 30번 15% 급여 인상.
조건 1. deptno 출력
조건 2. deptno 오름차순 정렬
select e.deptno, ename, sal, dname
,case e.deptno
when 10 then '5%'
when 20 then '20%'
when 30 then '15%'
else '0%'
end 인상율
,decode(e.deptno, 10, sal*1.05, 20, sal*1.2, 30, sal*1.15, sal) 디코드
,case e.deptno
when 10 then sal*1.05
when 20 then sal*1.2
when 30 then sal*1.15
else sal
end 케이스
from emp e join dept d on e.deptno = d.deptno
order by deptno;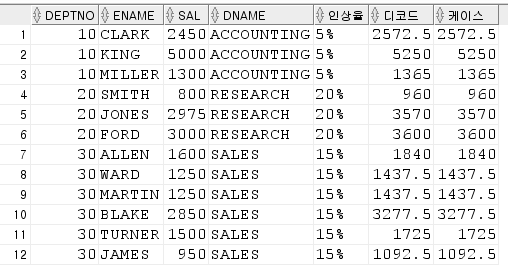
JOIN 간단히 설명
- 부서명/사원명/입사일자 를 출력하고싶다
(dname ename hiredate)
- dname은 dept 테이블에 있고 나머지는 emp에 있다.
- 위의 두 테이블은 deptno 컬럼 관계
- 두 테이블을 합쳐서 (조인)
- select dname, ename, hiredate 엄밀히 따지면 밑과 같다
select dept.deptno, emp.deptno, dept.dname, emp.ename, emp.hiredate- 앞에 스키마를 안 적어도 dname은 dept에밖에 없고 뒤에 나머지도 마찬가지니 생략 가능
- deptno는 양 테이블 모두에 있으니 앞에 스키마 명시가 필수적
- join 뒤에는 on이 필수
from emp join dept on dept.deptno = emp.deptno;-1- join 규칙을 on 뒤에 쓰는 경우
select e.deptno, dname, ename, sal
from emp e join dept d on e.deptno = d.deptno; --join 규칙을 on 뒤에 쓰는 경우-2- join 키워드를 쓰지 않는 경우 (크로스 조인)
select e.deptno, dname, ename, sal
from emp e, dept d
where e.deptno = d.deptno;
3. insa 에서 사원들의 만나이 계산해서 출력
1) ssn 성별 1800/1900/2000
2) ssn 생일 월, 일
3) ssn 년
select name
, "금년"
,"4자리년도"
, "금년" - "4자리년도" 연나이
,sysdate
,ssn
,case
when (sysdate-to_date("생일", 'mmdd'))<0 then "금년"-"4자리년도"-1
else "금년"-"4자리년도" --여기서 "" 필수
end "만나이"
from (
select name, ssn
,substr(ssn, 0,2) as "년도"
,substr(Ssn, 3,4) as "생일"
,substr(ssn, 8,1) as "성"
,to_char(sysdate, 'yyyy') as "금년"
,case
when substr(ssn,8,1) in (1,2,5,6) then 1900+substr(ssn,0,2)
when substr(ssn,8,1) in (3,4,7,8) then 2000+substr(ssn,0,2)
else 1800+substr(ssn,0,2)
end "4자리년도"
from insa) temp;
4. emp 테이블의 ename, pay , 최대pay값 5000을 100%로 계산해서 각 사원의 pay를 백분률로 계산해서 10% 당 별하나(*)로 처리해서 출력 (소숫점 첫 째 자리에서 반올림해서 출력 )
with temp as(
select ename, sal+nvl(comm,0) pay
,(select max(sal+nvl(comm,0)) from emp) max_pay
from emp
)
select ename, pay, max_pay
,concat(pay*100/max_pay, '%') percent
,round(pay*100/max_pay/10) star_count
,rpad(' ', round(pay*100/max_pay/10)+1, '*')
--첫번째는 빈공백' '찍었기 때문에 그 공간때문에+1
from temp;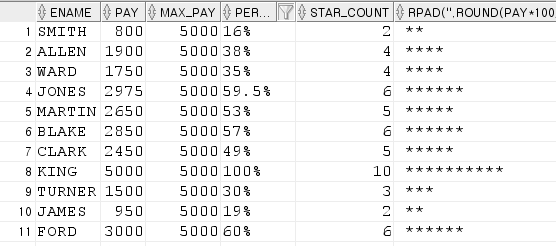
to_char(last_day(sysdate), 'dd') --문자형태
extract(day from last_day(sysdate)) -- 숫자형태 (그 외엔 똑같음)
* 그룹바이절에 있는 일반 컬럼은 select절에 쓸 수 있다.
select d.deptno, dname, max(sal), min(sal), sum(sal), avg(sal) a, count(*) c
--deptno, dname은 일반함수지만 group by절에 있어서 찍을 수 있는 거
from emp e join dept d on e.deptno = d.deptno
group by d.deptno, dname
order by d.deptno; --40번은 안나옴 - outer join 사용해야함 (면접때 엄청 물어봄)
- 상관서브쿼리 사용하기
10번 부서에서 가장 급여가 높은 사원 정보 출력
select deptno, ename, sal
from emp
where sal =(select max(sal) from emp where deptno = 10);
각 부서별 최고 급여 받는 사원 정보 출력
select o.deptno, o.ename
from emp o
where sal = (select max(sal)from emp i where i.deptno = o.deptno)
order by deptno;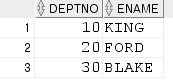
각 부서별 탑, 부서 탑 구하기
select deptno, ename, sal
,(select max(sal) from emp) 탑
,(select max(sal) from emp i where i.deptno = o.deptno ) 부서탑
--상관서브쿼리
--밑에 한 줄은 위의 부서탑과 같은 결과를 출력
,max(sal) over(partition by deptno) dept_max_sal
--해당 부서 최대 급여액 (암기)
from emp o
order by deptno;
5. emp 테이블에서 가장 급여 많이 받는 사원 5명 정보 출력
select rownum, t.*
from (
select *
from emp
order by sal desc
)t
where rownum<=5;
6. 각 부서별 남,여 인원수 파악
- 답1
select buseo, decode(mod(substr(ssn,8,1),2),1,'남자','여자' ) geneder
, count(*)
from insa
group by buseo, decode(mod(substr(ssn,8,1),2),1,'남자','여자' )
order by buseo;- 답2
with temp as(
select buseo
,decode(mod(substr(ssn,8,1),2),1,'남자','여자' ) gender
from insa
)
select buseo, gender, count(*) -- temp.*, count(*) 같은 의미
from temp
group by buseo, gender
order by buseo;- 출력
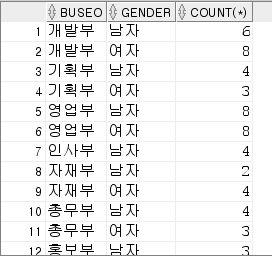
7. 각 부서별 인원수를 파악해 7명 이상인 부서만 출력
select buseo, count(*) cnt
from insa
group by buseo
having count(*)>=7 --group by의 조건절이 having이다.
order by cnt desc;8. 각 부서별 남자사원 수가 5명 이상인 부서만 출력
-답1 (이게 BEST)
select buseo, count(*)
from insa
where mod(substr(ssn,8,1),2)=1 --남자만 찍고
group by buseo --그제서야 group by
having count(*)>=5;-답2
select buseo
,count(decode(substr(ssn,8,1),1,'O')) 남
from insa
group by buseo
having count(decode(substr(ssn,8,1),1,'O'))>=5
order by buseo;
- 부서별로 파티션을 나눠 카운팅하겠다
select distinct deptno, count(*) over(partition by deptno)
--부서별로 파티션을 나눠 카운팅하겠다
from emp;
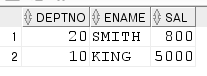
9. 최고, 최저 급여 사원 정보
-답1
select deptno, ename, sal
from emp
where sal in (5000, 800);-답2
select deptno, ename, sal
from emp
--where sal in (max(sal), min(sal));
--ORA-00934: group function is not allowed here
--그룹합수를 사용할 수 없는 곳이다
where sal in( (select max(sal) from emp)
,(select min(sal) from emp)
--,(select max(sal), min(sal) from emp) 오류, too many values
--값이 행으로 나와야하는데 옆으로 나온다고
); 
* dbms_random 패키지
- 자바의 Math.random()
- 패키지 의미가 자바와 다르다, PL/SQL의 한 종류라고 기억
select dbms_random.value -- 0.0<=실수<1.0 랜덤 출력
,dbms_random.value(0,45) -- 0<= 실수 <45
,trunc(dbms_random.value(0,45))+1 --정수가 될 것 +1:로또번호 1~45
,dbms_random.string('U', 5) --대문자 5개 출력
,dbms_random.string('L', 5) --소문자 5개 출력
,dbms_random.string('A', 5) --대문자 + 소문자 5개 출력
,dbms_random.string('X', 5) --대문자 + 숫자 5개 출력
,dbms_random.string('P', 5) --대문자 + 소문자 + 숫자 + 특문 5개 출력
from dual;
10. emp 테이블에서 각 월별로 입사한 사원수 출력
select extract(month from hiredate)
,count(*)
from emp
group by extract(month from hiredate);
order by extract(month from hiredate);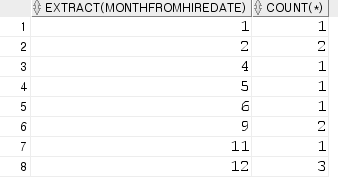
select
-- count(*) 총사원수
--decode(to_char(hiredate, 'mm'))
--to_char(hiredate, 'mm') --문자 01 02
--extract(month from hiredate) --숫자 1 2
count(decode( to_char(hiredate, 'mm'), '01', 'O')) "01월"
, count(decode( to_char(hiredate, 'mm'), '02', 'O')) "02월"
, count(decode( to_char(hiredate, 'mm'), '03', 'O')) "03월"
, count(decode( to_char(hiredate, 'mm'), '04', 'O')) "04월"
, count(decode( to_char(hiredate, 'mm'), '05', 'O')) "05월"
, count(decode( to_char(hiredate, 'mm'), '06', 'O')) "06월"
, count(decode( to_char(hiredate, 'mm'), '07', 'O')) "07월"
, count(decode( to_char(hiredate, 'mm'), '08', 'O')) "08월"
, count(decode( to_char(hiredate, 'mm'), '09', 'O')) "09월"
, count(decode( to_char(hiredate, 'mm'), '10', 'O')) "10월"
, count(decode( to_char(hiredate, 'mm'), '11', 'O')) "11월"
, count(decode( to_char(hiredate, 'mm'), '12', 'O')) "12월"
from emp;
피벗(pivot) / 언피벗(unpivot)
- pivot( 집계함수 for XXX in (목록 서브쿼리X aliasO ) );
- 세로로된 결과물을 가로로 나타내는 것
- 오라클11g 부터 추가된 pivot 절을 사용하지 않는다면 decode(), case() + count() + group by()절을 응용하면 됨
smith 20 10 20 30 40
allen 30 -> 2 1
jone 20
위의 코딩을 피벗을 사용해 수정
select *
from(
select --ename, hiredate,
extract( month from hiredate) month
from emp
)
pivot (count(month) for month in(1,2,3,4,5,6,7,8,9,10,11,12) );
-- 실제 출력 데이터 가로줄로 표기할 열
11. 각 년도별 입사한 사원수 조회 - 피벗
select *
from(
select --ename, hiredate,
extract( year from hiredate) year
-- extract( month from hiredate) month
from emp
)
pivot (count(year) for year in(1980, 1981, 1982) );
11-2) 입사년도별/월별 사원수 - 피벗
select *
from(
select
extract( year from hiredate) year
,extract( month from hiredate) month
from emp
)
pivot (count(month) for month in(1,2,3,4,5,6,7,8,9,10,11,12) );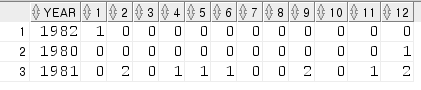
12) 각 부서의 사원 수 구하기 - 피벗
select *
from(--인라인 뷰
select deptno
from emp
)
--pivot( 집계함수 for deptno in (목록 서브쿼리X aliasO ) );
pivot (count(deptno) for deptno in(10,20,30,40) );
13) 부서별 - 남자 총 급여합 / 여자 총 급여합
select *
from(
select buseo
,decode( mod(substr(ssn,8,1),2) ,1, '남자','여자') gender
,basicpay
from insa --안쪽만 드래그해서 돌려봐
)
pivot(sum(basicpay) for gender in('남자'as "남총급합",'여자') ); --alias 별칭은 가능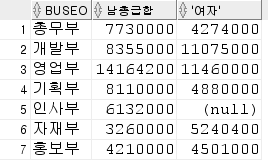
14) 등급 구하기
select deptno, ename, sal
,--등급(grade)
case
when sal between 700 and 1200 then 1
when sal between 1201 and 1400 then 2
when sal between 1401 and 2000 then 3
when sal between 2001 and 3000 then 4
when sal between 3001 and 9999 then 5
end grade
from emp;- 위의 쿼리를 JOIN을 사용해 수정
select deptno, ename, sal, grade
from emp e, salgrade s
where e.sal between s.losal and s.hisal;
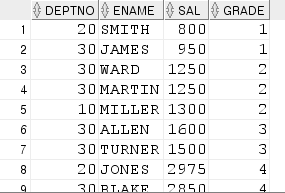
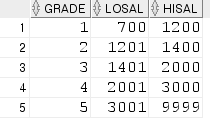
(참고) salgrade
'Oracle' 카테고리의 다른 글
| [days07] 오라클 data type(자료형) (0) | 2020.11.06 |
|---|---|
| [days07] SQL - RANK, ROLL UP (0) | 2020.11.06 |
| [days05] 집계함수 (0) | 2020.11.04 |
| [days05] SQL function2 (0) | 2020.11.04 |
| [days04] SQL Operation, Function 예제 (0) | 2020.11.03 |


